Introduction
This article is part 3 of a series of three articles that I am going to post. The proposed article content will be as follows:
- Part 1: This one will be an introduction into Perceptron networks (single layer neural networks)
- Part 2: Will be about multi-layer neural networks, and the back propagation training method to solve a non-linear classification problem such as the logic of an XOR logic gate. This is something that a Perceptron can't do. This is explained further within this article.
- Part 3: This one is about how to use a genetic algorithm (GA) to train a multi-layer neural network to solve some logic problem, ;f you have never come across genetic algorithms, perhaps my other article located here may be a good place to start to learn the basics.
Summary
This article will show how to use a Microbial Genetic Algorithm to train a multi-layer neural network to solve the XOR logic problem.
A Brief Recap (From Parts 1 and 2)
Before we commence with the nitty griity of this new article which deals with multi-layer neural networks, let's just revisit a few key concepts. If you haven't read
Part 1 or
Part 2, perhaps you should start there.
Part 1: Perceptron Configuration (Single Layer Network)
The inputs (x1,x2,x3..xm) and connection weights (w1,w2,w3..wm) in figure 4 are typically real values, both positive (+) and negative (-). If the feature of some xi tends to cause the perceptron to fire, the weight wi will be positive; if the feature xi inhibits the perceptron, the weight wi will be negative.
The perceptron itself consists of weights, the summation processor, and an activation function, and an adjustable threshold processor (called bias hereafter).
For convenience, the normal practice is to treat the bias as just another input. The following diagram illustrates the revised configuration:
The bias can be thought of as the propensity (a tendency towards a particular way of behaving) of the perceptron to fire irrespective of its inputs. The perceptron configuration network shown in Figure 5 fires if the weighted sum > 0, or if you are into math type explanations.
Part 2: Multi-Layer Configuration
The multi-layer network that will solve the XOR problem will look similar to a single layer network. We are still dealing with inputs / weights / outputs. What is new is the addition of the hidden layer.
As already explained above, there is one input layer, one hidden layer, and one output layer.
It is by using the inputs and weights that we are able to work out the activation for a given node. This is easily achieved for the hidden layer as it has direct links to the actual input layer.
The output layer, however, knows nothing about the input layer as it is not directly connected to it. So to work out the activation for an output node, we need to make use of the output from the hidden layer nodes, which are used as inputs to the output layer nodes.
This entire process described above can be thought of as a pass forward from one layer to the next.
This still works like it did with a single layer network; the activation for any given node is still worked out as follows:
where wi is the weight(i), and Ii is the input(i) value. You see it the same old stuff, no demons, smoke, or magic here. It's stuff we've already covered.
So that's how the network looks. Now I guess you want to know how to go about training it.
Learning
There are essentially two types of learning that may be applied to a neural network, which are "Reinforcement" and "Supervised".
Reinforcement
In Reinforcement learning, during training, a set of inputs is presented to the neural network. The output is 0.75 when the target was expecting 1.0. The error (1.0 - 0.75) is used for training ("wrong by 0.25"). What if there are two outputs? Then the total error is summed to give a single number (typically sum of squared errors). E.g., "your total error on all outputs is 1.76". Note that this just tells you how wrong you were, not in which direction you were wrong. Using this method, we may never get a result, or could be hunt the needle.
Using a generic algorithm to train a multi-layer neural network offers a Reinforcement type training arrangement, where the mutation is responsible for "jiggling the weights a bit". This is what this article is all about.
Supervised
In Supervised learning, the neural network is given more information. Not just "how wrong" it was, but "in what direction it was wrong", like "Hunt the needle", but where you are told "North a bit" "West a bit". So you get, and use, far more information in Supervised learning, and this is the normal form of neural network learning algorithm.
This training method is normally conducted using a Back Propagation training method, which I covered in
Part 2, so if this is your first article of these three parts, and the back propagation method is of particular interest, then you should look there.
So Now the New Stuff
From this point on, anything that is being discussed relates directly to this article's code.
What is the problem we are trying to solve? Well, it's the same as it was for
Part 2, it's the simple XOR logic problem. In fact, this articles content is really just an incremental build, on knowledge that was covered in
Part 1 and
Part 2, so let's march on.
For the benefit of those that may have only read this one article, the XOR logic problem looks like the following truth table:
Remember with a single layer (perceptron), we can't actually achieve the XOR functionality as it's not linearly separable. But with a multi-layer network, this is achievable.
So with this in mind, how are we going to achieve this? Well, we are going to use a Genetic Algorithm (GA from this point on) to breed a population of neural networks that will hopefully evolve to provide a solution to the XOR logic problem; that's the basic idea anyway.
So what does this all look like?
As can be seen from the figure above, what we are going to do is have a GA which will actually contain a population of neural networks. The idea being that the GA will jiggle the weights of the neural networks, within the population, in the hope that the jiggling of the weights will push the neural network population towards a solution to the XOR problem.
So How Does This Translate Into an Algorithm
The basic operation of the Microbial GA training is as follows:
That's it. That is the complete algorithm.
But there are some essential issues to be aware of when playing with GAs:
- The genotype will be different for a different problem domain
- The fitness function will be different for a different problem domain
These two items must be developed again whenever a new problem is specified. For example, if we wanted to find a person's favourite pizza toppings, the genotype and fitness would be different from that which is used for this article's problem domain.
These two essential elements of a GA (for this article problem domain) are specified below.
1. The Geneotype
For this article, the problem domain states that we had a population of neural networks. So I created a single dimension array of NeuralNetwork objects. This can be seen from the constructor code within the GA_Trainer_XOR object:
Hide Copy Code
private NeuralNetwork[] networks;
public GA_Trainer_XOR()
{
networks = new NeuralNetwork[POPULATION];
for (int i = 0; i <= networks.GetUpperBound(0); i++)
{
networks[i] = new NeuralNetwork(2, 2, 1);
networks[i].Change +=
new NeuralNetwork.ChangeHandler(GA_Trainer_NN_Change);
}
}
2. The Fitness Function
Remembering the problem domain description stated, the following truth table is what we are trying to achieve:
So how can we tell how fit (how close) the neural network is to this ? It is fairly simply really. What we do is present the entire set of inputs to the Neural Network one at a time and keep an accumulated error value, which is worked out as follows:
Within the NeuralNetwork class, there is a getError(..) method like this:
Hide Copy Code
public double getError(double[] targets)
{
double error = 0.0;
error = Math.Sqrt(Math.Pow((targets[0] - outputs[0]), 2));
return error;
}
Then in the NN_Trainer_XOR class, there is an Evaluate method that accepts an int value which represents the member of the population to fetch and evaluate (get fitness for). This overall fitness is then returned to the GA training method to see which neural network should be the winner and which neural network should be the loser.
Hide Copy Code
private double evaluate(int popMember)
{
double error = 0.0;
for (int i = 0; i <= train_set.GetUpperBound(0); i++)
{
forwardWeights(popMember, getTrainSet(i));
double[] targetValues = getTargetValues(getTrainSet(i));
error += networks[popMember].getError(targetValues);
}
if (error < acceptableNNError)
{
bestConfiguration = popMember;
foundGoodANN = true;
}
return error;
}
So how do we know when we have a trained neural network? In this article's code, what I have done is provide a fixed limit value within the NN_Trainer_XOR class that, when reached, indicates that the training has yielded a best configured neural network.
If, however, the entire training loop is done and there is still no well-configured neural network, I simply return the value of the winner (of the last training epoch) as the overall best configured neural network.
This is shown in the code snippet below; this should be read in conjunction with the evaluate(..) method shown above:
Hide Copy Code
if (bestConfiguration == -1)
{
bestConfiguration = WINNER;
}
return networks[bestConfiguration];
So Finally the Code
Well, the code for this article looks like the following class diagram (it's Visual Studio 2005, C#, .NET v2.0):
The main classes that people should take the time to look at would be:
GA_Trainer_XOR: Trains a neural network to solve the XOR problem using a Microbial GA.TrainerEventArgs: Training event args, for use with a GUI.NeuralNetwork: A configurable neural network.NeuralNetworkEventArgs: Training event args, for use with a GUI.SigmoidActivationFunction: A static method to provide the sigmoid activation function.
The rest are the GUI I constructed simply to show how it all fits together.
Note: The demo project contains all code, so I won't list it here. Also note that most of these classes are quite similar to those included with the
Part 2 article code. I wanted to keep the code similar so people who have already looked at
Part 2 would recognize the common pattern.
Code Demos
The demo application attached has three main areas which are described below:
Live Results Tab
It can be seen that this has very nearly solved the XOR problem; it did however take nearly 45000 iterations (epoch) of a training loop. Remembering that we have to also present the entire training set to the network, and also do this twice, once to find a winner and once to find a loser. That is quite a lot of work; I am sure you would all agree. This is why neural networks are not normally trained by GAs; this article is really about how to apply a GA to a problem domain. Because the GA training took 45000 epochs to yield an acceptable result does not mean that GAs are useless. Far from it, GAs have their place, and can be used for many problems, such as:
- Sudoko solver (the popular game)
- Backpack problem (trying to optimize the use of a backpack of limited size, to get as many items in as will fit)
- Favourite pizza toppings problem (try and find out what someone's favourite pizza is)
To name but a few, basically, if you can come up with the genotype and a Fitness function, you should be able to get a GA to work out a solution. GAs have also been used to grow entire syntax trees of grammar, in order to predict which grammar is more optimal. There is more research being done in this area as I write this article; in fact, there is a nice article on this topic (
Gene Expression Programming) by Andrew Krillov, right here at the CodeProject, if anyone wants to read further.
Training Results Tab
Viewing the target/outputs together:
Viewing the errors:
Trained Results Tab
Viewing the target/outputs together:
It is also possible to view the neural network's final configuration using the "View Neural Network Config" button.
What Do You Think?
That is it; I would just like to ask, if you liked the article, please vote for it.
Points of Interest
I think AI is fairly interesting, that's why I am taking the time to publish these articles. So I hope someone else finds it interesting, and that it might help further someone's knowledge, as it has my own.
Anyone that wants to look further into AI type stuff, that finds the content of this article a bit basic, should check out Andrew Krillov's articles at
Andrew Krillov CP articles as his are more advanced, and very good.
History
- v1.1: 27/12/06: Modified the
GA_Trainer_XOR class to have a random number seed of 5.
- v1.0: 11/12/06: Initial article.
Bibliography
- Artificial Intelligence 2nd edition, Elaine Rich / Kevin Knight. McGraw Hill Inc.
- Artificial Intelligence, A Modern Approach, Stuart Russell / Peter Norvig. Prentice Hall.
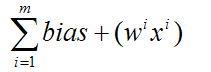




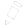 Submit an article or tip
Submit an article or tip

 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 
















0 Comments:
Post a Comment
Subscribe to Post Comments [Atom]
<< Home